
Studying data
Recommender Systems(1): Memory-based Collaborative Filtering 본문
추천 시스템은 크게 Content-based Filtering과 Collaborative Filtering으로 나뉜다. Collaborative Filtering은 다시 두가지 방식으로 나뉘는데, 하나는 Memory-based methods (aka Neighborhood-based)이고, 다른 하나는 Model-based methods이다.
Recommender Systems
- Collaborative Filtering(CF)
• Memory-based CF (aka Neighborhood-based)
• Model-based CF
- Content-based Filtering

이번 글에서는 Collaborative filtering 방법 중 Memory-based Collaborative Filtering에 대해서 다룰 것이다.
Collaborative Filtering(CF)
Collaborative Filtering(CF, 협업 필터링)은 유저-아이템 간 상호작용 데이터(user-item interaction data)를 활용하여 새로운 유저-아이템 관계를 찾아주는 방법론으로 유저의 과거 경험과 행동 방식(즉, 기존 데이터)에 의존해 추천하는 시스템이다. (기존 데이터가 더 많이 축적될수록 추천 시스템의 정확도가 높아진다.) 많은 유저들로부터 얻은 기호 정보에 따라 유저들의 관심사를 예측하는 방법이라고도 할 수 있다.
협업 필터링은 Domain Free 방식으로 관련 지식들이 불필요하다는 장점이 있다. 이 방법론은 missing rating values(사용자가 아직 rating을 하지 않은 부분)를 추정하거나 new recommendations를 위해 유저와 아이템 간 유사성을 찾는다. user similarity나 item similiarity를 계산하기 위한 방법에는 Cosine Similarity, Pearson Correlation 등이 있으며 이에 대해서는 뒤에서 설명할 것이다.
Explicit feedback vs Implicit feedback
앞서 언급했듯이 협업 필터링은 유저-아이템 간 상호작용 데이터를 활용해 추천하는 방식인데, 이 유저와 아이템 간의 상호작용, 즉 유저의 아이템에 대한 피드백을 나타내는 데이터에는 두가지 종류가 있다.
• Explicit feedback : 아이템에 대한 유저의 선호와 비선호를 직접적으로 나타내는 데이터. 보통 유저가 아이템을 얼마나 선호했는지 또는 비선호했는지를 numerical한 평점을 통해 나타냄(ex. 영화 평점, 맛집 별점). 평점이 높으면 선호, 낮으면 비선호로 판단. 유저가 직접 별점을 계속 매겨야하므로 데이터셋의 크기가 보통 작다.
• Implicit feedback : 서비스에서 유저가 한 행동을 기록한 데이터 (ex. 웹페이지에 머문 시간, 클릭 패턴, 검색 로그, 구매 여부, 장바구니 등). 예를 들어 유저가 아이템을 시청했거나(미디어의 경우) 클릭했을 때(웹사이트의 경우) 유저가 아이템에 관심을 보였다고 가정한다. 시청과 클릭만으로는 직접적으로 아이템에 대한 유저의 선호도를 알 수 없기 때문에 implicit feedback이라 한다. 또한 explicit feedback과 다르게 유저의 비선호 여부는 알 수 없다. (ex. 상품을 클릭하지 않았다고 해서 비선호라고 볼 수는 없기 때문. 단순히 해당 상품에 노출되지 않았을 수 있음) explicit feedback에 비해 데이터의 품질은 낮지만 데이터셋의 양이 보통 비교가 안 될만큼 크기 때문에 최신 추천 시스템은 implicit feedback 데이터를 통해 추천하는 방향으로 발전했다.

User-item matrix
협업 필터링의 학습에 주어지는 데이터는 유저-아이템 매트릭스(user-item matrix) 형태이다. 아래 그림에서 John이라는 유저와 아이템들의 관계는 [5, 1, 3, 5]와 같이 벡터로 표현할 수 있다. 유저-아이템 간 상호작용 데이터의 형태가 explicit feedback인 경우 유저가 아이템에 준 평점값을 매트릭스에 채워넣는다. 이 때 평점을 주지 않은 아이템은 매트릭스가 빈칸으로 남는데, 데이터가 explicit feedback인 경우 이 빈칸들을 채우는 것이 협업 필터링의 목표가 되고 이를 matrix completion이라 한다. 빈칸을 채우면, 즉 유저의 평점을 예측하고 나면 예측한 평점값에 따라 해당 유저에게 아이템을 추천하게 된다.

데이터가 implicit feedback인 경우, 유저가 아이템과 상호작용(interaction)이 있었다면(ex. 클릭한 경우) 1을, 없었다면 0을 주어 매트릭스를 채운다. explicit feedback 데이터셋은 평점 자체가 이미 아이템에 대한 선호도를 나타내기 때문에 평점 안에 positive, negative feedback 정보를 모두 담고 있다. 하지만 implicit feedback 데이터셋에는 positive feedback 정보 밖에 없다. interaction이 일어난 positive feedback에 대해서만 학습한다면 유저의 선호도를 학습하기 어렵기 때문에 implicit feedback 데이터셋에서는 missing data를 모두 잠정적인 negative feedback으로 보고 0으로 채운다. 따라서 implicit feedback 데이터셋으로 CF를 학습할 때는 matrix의 빈 공간을 채우는 것이 학습의 목표가 아니라 주어진 matrix에서 사용자의 선호 패턴을 알아내는 것이 목표가 된다.
Collaborative Filtering의 한계
• 콜드 스타트(Cold Start Problem) : 많은 사용자로부터 얻은 기호 정보를 이용하는 협업 필터링이기에 협업 필터링 알고리즘 사용을 위해서는 어느 정도의 기존 데이터가 마련되어 있어야 한다. 이때 새로운 유저나 새로운 아이템에 대한 기존 데이터가 부족하면 추천 시스템이 유저에게 아이템을 추천하기 어려운 문제가 발생하는데 이를 Cold Start Problem이라 한다.
• 계산 효율 저하 : 협업 필터링은 계산량이 많은 알고리즘이기에 유저가 많아질수록 계산 시간이 오래걸려 추천의 효율성이 떨어진다. 유저의 수가 일정 수준 이상이어야 정확한 결과를 낼 수 있지만 계산 시간이 그에 비례해 늘어나는 것이 협업 필터링의 딜레마이다.
• 롱테일(Long Tail) : 소수의 인기 아이템들이 전체 추천 아이템의 많은 비율을 차지하는 비대칭적 쏠림 현상. 인기없는 아이템들은 추천되지 않는 문제가 발생한다.
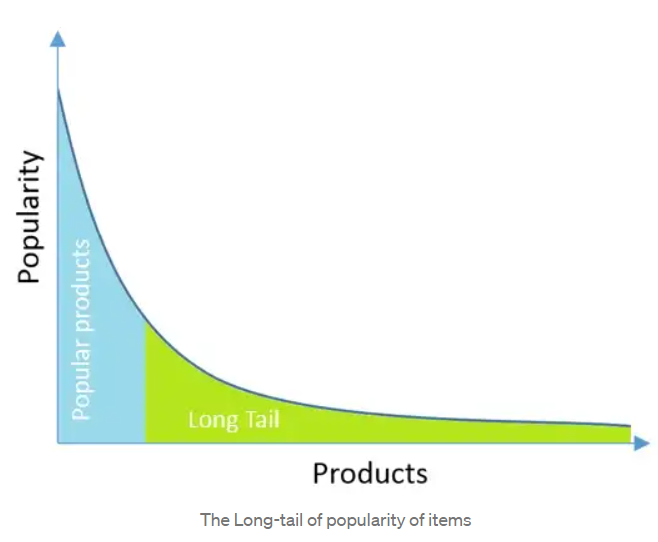

Memory-based Collaborative Filtering (aka Neighborhood-based)
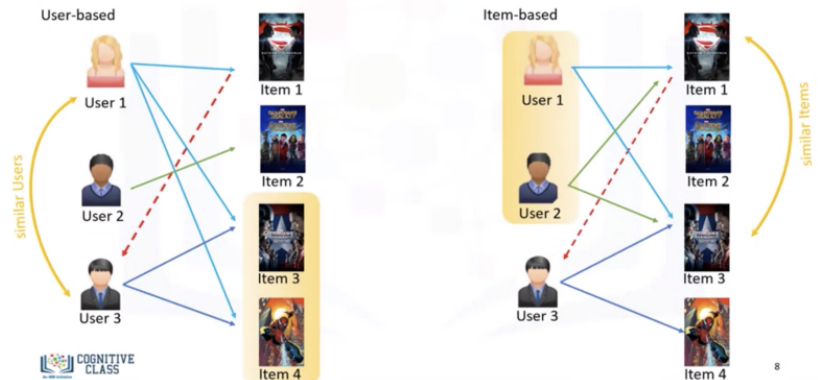
앞에서 Collaborative Filtering은 Memory-based CF와 Model-based CF로 나뉜다고 했었다. Memory-based CF가 Model-based CF와 구별되는 가장 핵심 차이는 gradient descent(경사하강법)와 같은 최적화 알고리즘을 사용해 파라미터를 학습시키지 않는다는 점이다. 가장 유사한 유저나 아이템이 단지 코사인 유사도나 피어슨 상관계수와 같은 산술 연산에 의해서만 계산된다. 즉, parametric ML approach를 사용하지 않는 방법이 Memory-based CF로 분류되는 것이다. Memory-based CF는 non-parametric ML approach인 K-Nearest Neighbors(KNN)이 기반이며, 다시 User-based와 Item-based collaborative filtering으로 나뉜다.
1. User-based Collaborative Filtering (유저 기반의 근접 이웃 방법)
user-based method에서는 비슷한 아이템들에 타겟 유저와 비슷하게 평점을 준 비슷한 유저들을 찾은 다음, 비슷한 유저가 상호작용한 아이템들 중 타겟 유저가 아직 상호작용을 하지 않은 아이템(unobserved items)에 대한 타겟 유저의 평점을 예측한다 (즉, 타겟 유저가 아직 접하지 않아서 평점을 주지 않은 아이템에 대해 얼마나 평점을 줄 것인가를 예측하는 것). 여기서 타겟 유저의 평점은 비슷한 유저들이 해당 아이템에 준 평점을 기반으로 예측한다. 그렇게 해서 나온 평점 예측값이 지정한 임계값보다 높으면 타겟 유저에게 추천을 해주거나, 평점 예측값이 높은 상위 n개의 아이템을 추천한다.
(또는 더 간단하게 타겟 유저와 유사한 유저가 소비한 아이템 중 타겟 유저가 아직 접하지 않은 아이템을 타겟 유저에게 추천하는 방식)
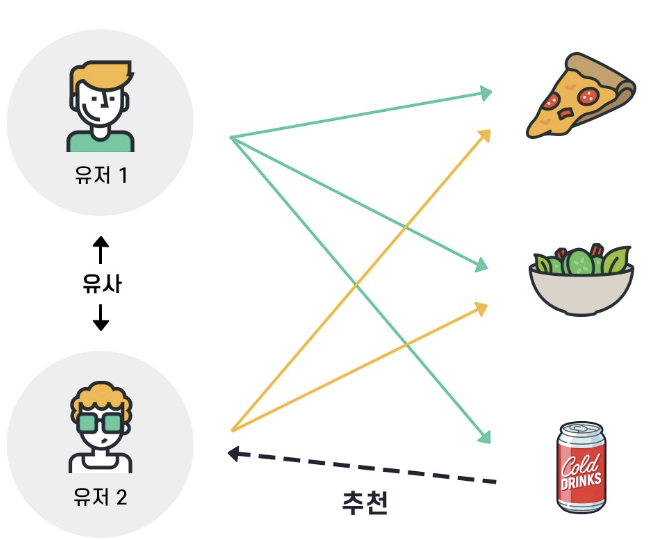
Ex.
예를 들어 Alice와 Bob이라는 유저가 영화에 대해 다음과 같이 비슷한 평점을 줬다고 해보자.
Alice = {Terminator: 4, Predator: 2, Robocop: 3}
Bob = {Terminator: 4, Predator: 2, Robocop: ?}
user-based CF의 목적은 타겟 유저가 아직 평점을 주지 않은 아이템(unobserved items)에 대한 타겟 유저의 평점을 예측하는 것이다. Bob이 타겟유저라면 Bob이 아직 보지 않은 영화인 Robocop에 대한 Bob의 평점을 Bob과 비슷한 유저인 Alice가 Robocop에 준 평점을 기반으로 예측한다.
User-based CF의 step
1) 타겟 유저를 정한다.
2) 타겟 유저와 비슷하게 평점을 준 비슷한 유저를 찾는다. (한 명 이상일 수 있음)
3) 타겟 유저가 아직 한번도 상호작용한 적이 없는 아이템(unobserved items)을 추출한다.
4) unobserved items에 대한 타겟 유저의 평점을 비슷한 유저의 평점을 기반으로 예측한다.
5) 예측한 평점이 임계값(threshold)보다 높다면 해당 unobserved items를 타겟 유저에게 추천한다. (또는 예측 평점이 높은 상위 n개의 아이템을 추천)
User-based CF가 어떻게 이루어지는지 구체적으로 살펴보자.
STEP 1. 유저 간 유사도 구하기
타겟 유저와 비슷한 유저를 찾기 위해서는 유저 벡터 간 유사도를 계산해야 한다. 유사도를 구하는 방법에는 크게 코사인 유사도(Cosine similarity)와 피어슨 유사도(Pearson similarity, aka. Centered Cosine similarity)가 있다. 전체 사용자 간의 유사도를 계산해서 유사도 행렬을 구한다.
• 코사인 유사도(Cosine similarity)
코사인 유사도는 두 벡터(유저)가 같은 방향성을 띠고 있는지를 평가한다. -1 이상 1 이하의 값을 가지며 1에 가까울수록 유사도가 높다.

두 벡터 A, B에 대한 코사인 유사도는 식으로 표현하면 다음과 같다.
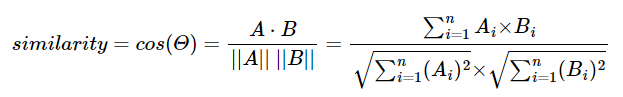
사용자 u와 u' 의 ratings vector(R)에 대한 코사인 유사도 식은 다음과 같다.

아래 예시에서 유저 A와 B, 유저 A와 C 간의 코사인 유사도를 구해보면 다음과 같다. 코사인 유사도를 구할 때 유저가 평점을 주지 않은 빈칸(missing ratings)은 0으로 간주한다. 코사인 유사도는 유저나 아이템의 평균 평점을 구할 필요가 없기 때문에 계산에 있어서는 피어슨 유사도보다 효율적이다. 하지만 유저가 아직 평점을 주지 않은 부분(missing ratings)을 0으로 놓고 계산하기 때문에 미평가 항목이 negative한 평점을 받은 것으로 간주하게 되는 문제가 있다. 이러한 이유로 피어슨 유사도를 사용한다.

위 자료의 경우 코사인 유사도 식의 분모에서 유저들이 평점을 준 모든 아이템을 사용했지만 공통으로 평점을 준 아이템만 사용해야 한다고 말하는 글이나 강의들도 있었다. 위 자료에서는 A와 B의 유사도를 구할 때 분모에서 유저 A가 평점을 준 HP1, TW, SW1의 평점을 모두 사용했고, 유저 B가 평점을 준 HP1, HP2, HP3의 평점을 모두 사용했다. 하지만 후자의 말대로라면 유저 A와 B가 공통으로 평점을 준 HP1만 사용하여 아래와 같이 유사도를 계산해야 한다. 유저 A, C의 경우 공통으로 평점을 준 TW, SW1만을 사용해야 한다.
$$sim(A,B) = \frac {4*5}{\sqrt{4^2}*\sqrt{5^2}}$$
$$sim(A,C) = \frac {5*2 + 1*4}{\sqrt{5^2 + 1^2}*\sqrt{2^2 + 4^2}}$$
• 피어슨 유사도(Pearson similarity, aka. Centered Cosine similarity)
피어슨 유사도는 평균적인 경향성에서 얼마나 차이가 나는지를 기반으로 한다. normalized된(평균을 뺌) 코사인 유사도를 사용하는 것이기 때문에 Centered Cosine similarity라고도 한다. 피어슨 상관계수가 1이면 완벽한 양의 선형 상관관계, 0이면 선형 상관관계 없음, -1은 완벽한 음의 선형 상관관계가 있음을 나타낸다.

피어슨 유사도 공식은 아래와 같은데,
1) 각 벡터의 평균을 구해서 0이 아닌 원소에서 빼주어 normalization하고,
2) normalized된 두 벡터 사이의 코사인 유사도를 계산하는 것이다.
여기서 x와 y는 각각 유저와 아이템 간 상호작용을 나타낸 벡터이다.

둘은 같은 식

아래 예시에서 역시 normalize 후 미평가 항목(missing ratings) 칸들은 0으로 채워넣고 피어슨 유사도를 계산하게 된다. 평점을 normalize하고 나면 결국 각 유저별 평균 평점은 모두 0이 되기 때문에 피어슨 유사도에서는 코사인 유사도에서와 달리 미평가 항목들을 평균 평점으로 간주하고 계산하는 효과가 있다. 또한 유저마다 기준이 달라 평점을 짜게 주는 유저가 있을 수 있고(tough raters) 후하게 주는 유저(easy raters)가 있을 수 있는데, 유저별 평균으로 normalize하기 때문에 피어슨 유사도는 이 문제 또한 handle한다는 장점이 있다.
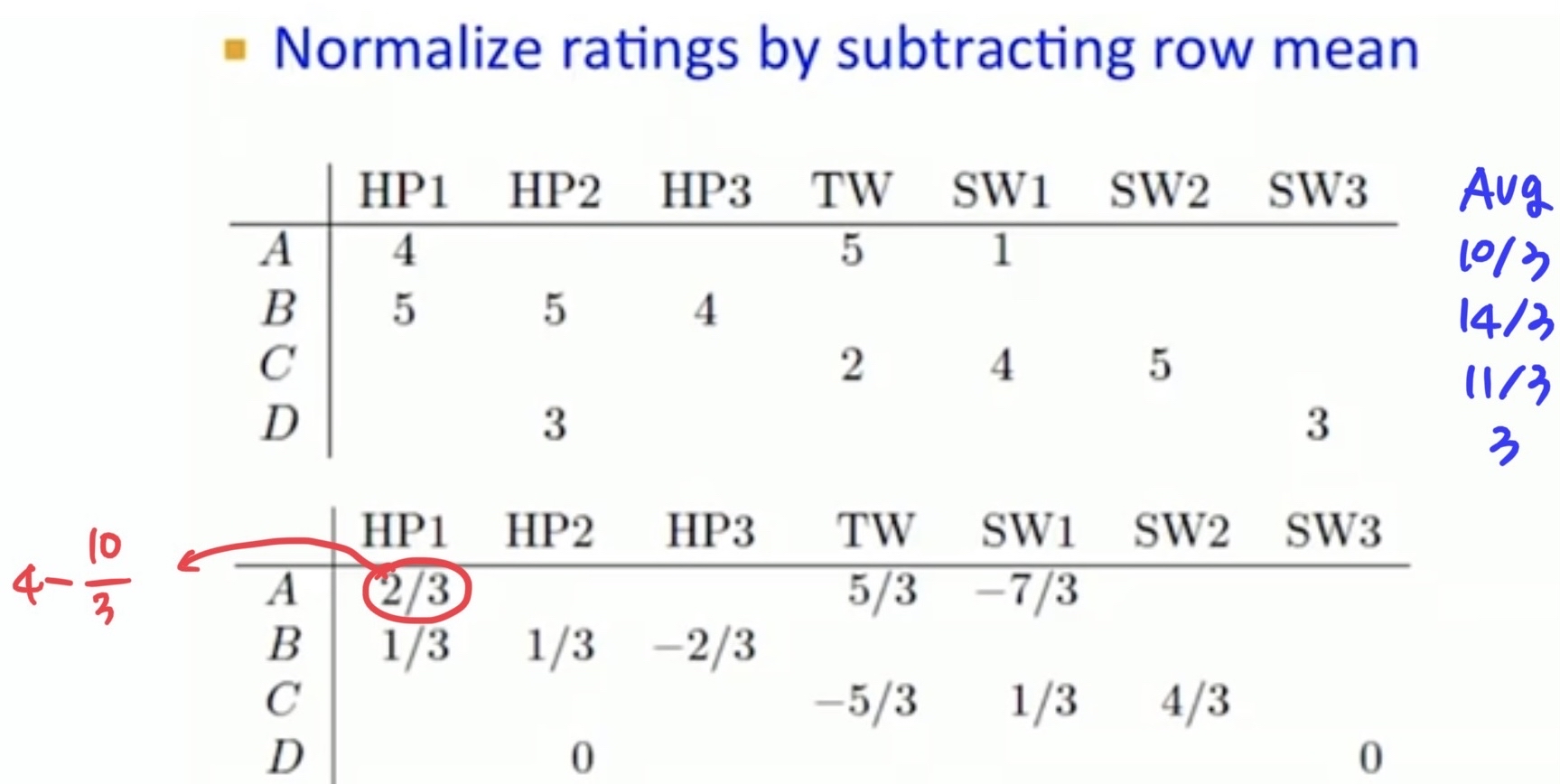
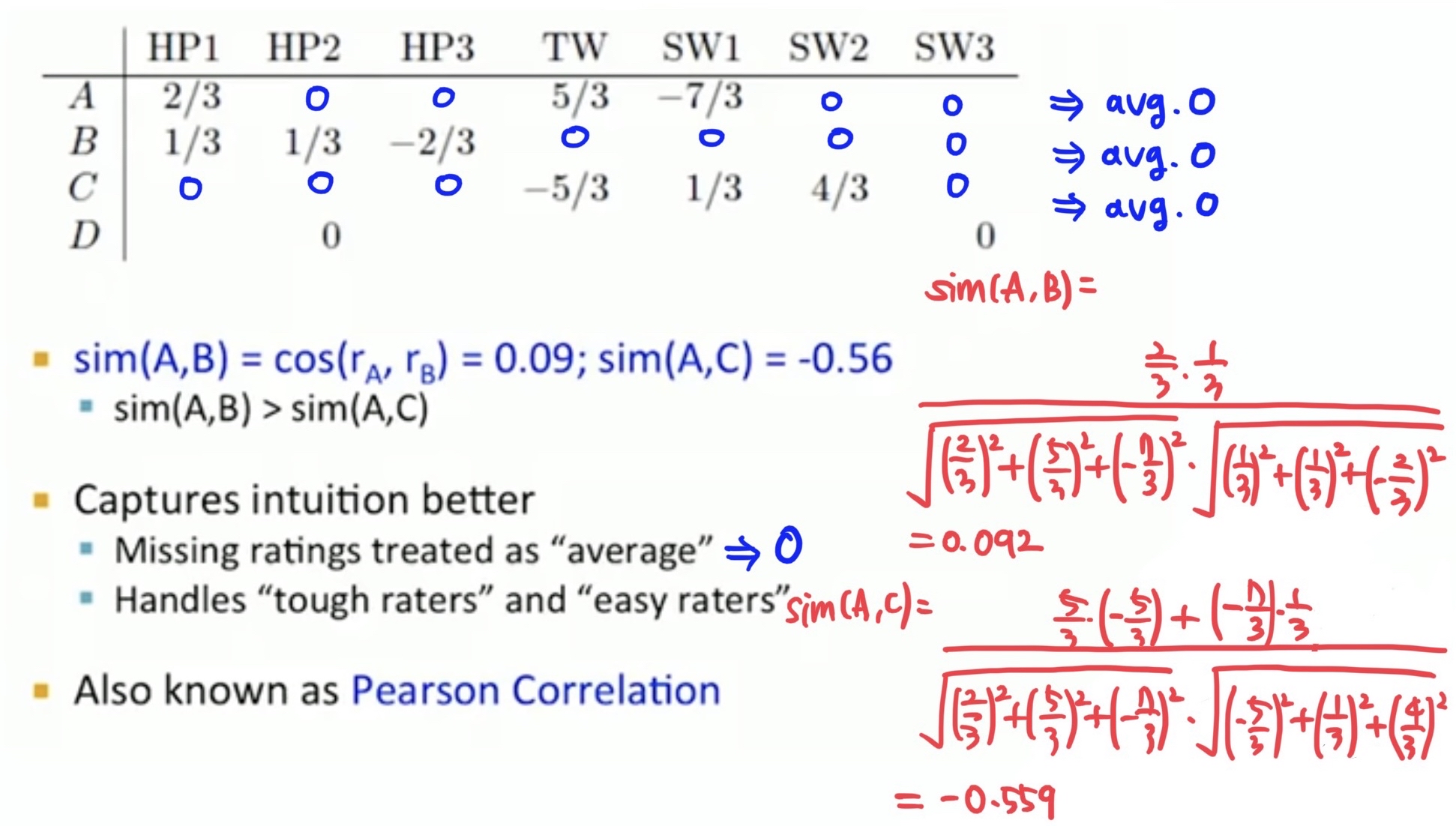
피어슨 유사도 또한 앞서 코사인 유사도 부분에서 언급했던 것과 같이 분모 부분에 두 사용자가 공통으로 평점을 준 아이템만을 사용해 구해야 한다는 자료들이 있었다. 이 경우 피어슨 유사도는 아래와 같이 계산된다.
$$sim(A,B) = \frac {2/3*1/3}{\sqrt{(2/3)^2}*\sqrt{(1/3)^2}}$$
$$sim(A,C) = \frac {5/3*(-5/3) + (-7/3)*(1/3)}{\sqrt{(5/3)^2 + (-7/3)^2}*\sqrt{(-5/3)^2 + (1/3)^2}}$$
이외에도 다양한 유사도 알고리즘이 있다.
• 유클리디안 거리(Euclidean distance) 점수 기반 유사도

• 자카드 유사도(Jaccard similarity)
자카드 계수(Jaccard coefficient), 자카드 지수(Jaccard index)라고도 한다. 두 집합 사이의 유사도를 측정하는 방법으로 합집합과 교집합 사이의 비율이라고 할 수 있다. 자카드 지수는 0과 1 사이의 값을 가지며, 두 집합이 동일하면 1의 값을 가지고, 공통의 원소가 하나도 없으면 0의 값을 가진다.
예를 들어 X=[A,B,C,D], Y=[A,C,F,G]인 집합 X와 Y가 있다고 하면 합집합은 Union(X, Y) = [A,B,C,D,F,G] 이고, 교집합은 Intersection(X,Y) = [A, C] 임을 알 수 있다. 이 때 자카드 유사도는 (교집합의 원소 개수)/(합집합의 원소 개수)로 2/6=0.33이 된다.

출처: https://www.slideshare.net/springloops/collaborative-filtering-23732558
참고: https://wooono.tistory.com/132
https://abluesnake.tistory.com/100
여기까지는 STEP 1, 유사도를 구하는 과정이었다.
STEP 2. 타겟 유저의 평점 예측하기
이제 유저간 유사도를 구했으니 타겟 유저의 평점을 예측해야 한다. 여기서 K-Nearest Neighbors(KNN)의 개념이 쓰이는데 이는 가장 유사한 k개의 neighbors를 통해 예측하는 방법이다.
타겟 유저의 평점을 구하는 방법은 세 가지로 구분할 수 있다.
Option 1: 타겟 유저와 가장 유사한 k명의 유저들의 아이템에 대한 평점 평균내기 (average)
Option 2: 타겟 유저와 가장 유사한 k명의 유저와 타겟 유저 간의 유사도(ex. 코사인, 피어슨)를 가중치로 하여 아이템에 대한 가중 평균 구하기 (weighted average)
Option 3: Option 2에서 편향을 제거한 방법. (유저의 아이템 평점 - 유저의 평균 평점)과 유사도로 가중 평균을 구한 다음 타겟 유저의 평균 평점에 더하기


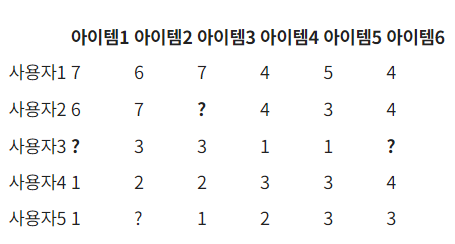
위와 같이 유저가 아이템에 대해 평가한 데이터가 주어져 있다고 할 때, 사용자 B의 아이템 4번에 대한 평점을 예측해보자. 먼저 전체 사용자 간 유사도를 계산하여 아래와 같은 유사도 행렬을 얻을 수 있다. 아래 유사도 행렬은 코사인 유사도로 구한 것으로 두 사용자가 공통으로 평점을 준 아이템만 사용했다. 사용자 B와 D간 코사인 유사도를 구한다 하면 다음과 같이 계산한다.
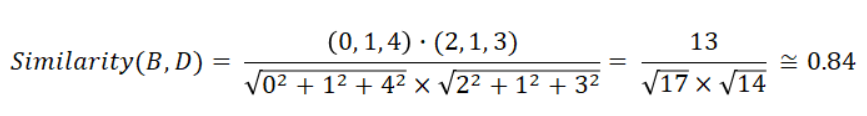

Option 1:
단순히 유사한 유저들의 평점을 평균내어 평점을 예측해보자. 사용자 B의 아이템 4번에 대한 평점을 예측해야 하므로 아이템 4번에 이미 평점을 준 사용자 중 B와 유사한 사용자들의 평점을 평균내면 된다. 여기서는 3-Nearest Neighbors로 하여 아이템 4번에 평점을 준 사용자 중 사용자 B와 가장 유사도가 높은 3명 A, D, E의 평점을 평균냈다. (KNN: 타겟 유저와 유사도가 가장 높은 k명의 유저의 평점을 평균)
$$Prediction = \frac {3 + 4 + 4}{3} \cong 3.67$$
Option 2:
유저 간의 유사도를 가중치로 한 가중평균을 내어 평점을 예측해보면 다음과 같다. Option 1에서와 마찬가지로 타겟 유저와 가장 유사한 3명의 사용자 A, D, E의 평점을 사용하고, 사용자 B와 A, D, E 간 유사도를 가중치로 둔다.
$$Prediction = \frac {0.84 × 3 + 0.84 × 4 + 0.63 × 4}{0.84 + 0.84 + 0.63} \cong 3.64$$
Option 3:
하지만 Option 2와 같이 계산한 값에는 "편향"이 존재하는데 편향은 유저 간에 평점을 어느 정도로 후하게 주는지의 차이 때문에 생기는 것이다. 이를 막기 위해 유저의 아이템 평점에서 유저의 평균 평점을 빼 평점을 수정한다. (평점을 수정하고 나면 각 유저의 평균 평점은 모두 0이 된다.) 그리고 수정한 평점과 유사도로 가중평균을 계산한 후 타겟 유저의 평균 평점에 더하면 된다.
사용자 A의 평균 평점: 4
사용자 D의 평균 평점: 2.5
사용자 E의 평균 평점: 3.5
타겟 유저 B의 평균 평점: 1.5
$$Prediction = 1.5 + \frac {0.84 × (3 - 4) + 0.84 × (4 - 2.5) + 0.63 × (4 - 3.5)}{0.84 + 0.84 + 0.63} \cong 1.82$$
유저별 평점을 주는 경향성을 반영하니 사용자 B의 아이템 4번에 대한 예측 평점이 Option 2의 3.64에서 1.82로 낮아진 것을 확인할 수 있다. 이는 평점을 짜게 주는 경향이 있는 B에 더 그럴듯한 예측 평점인 것 같다.
STEP 3. 타겟 유저에게 아이템 추천하기
이렇게 타겟 유저의 평점을 예측하여 유저-아이템 매트릭스의 빈칸을 모두 채웠다면 예측 평점이 높은 순으로 아이템을 내림차순 정렬하여 상위권에 랭크된 아이템들을 타겟 유저에게 추천해주거나, 예측 평점이 임계값(threshold)을 넘은 아이템들을 추천해 줄 수 있다.
[User-based CF 예시] (더보기 클릭)



User-based CF의 장점과 단점
User-based CF의 장점은 구현하기 쉽다는 점이다. 그리고 도메인 지식이 필요한 Contents-based CF에 비해 도메인에 대한 이해 없이도 구매 기록 또는 평점 기록만 있다면 손쉽게 적용할 수 있다. 어떤 산업인지 크게 구애받지 않는 셈이다.
단점이라고 하면 인풋인 평점 데이터의 희소성(Sparsity)이다. 유저들은 리뷰/평점을 잘 남기지 않기 때문에 인풋 데이터가 부족해진다. explicit feedback인 평점 데이터 대신 구매 기록, 클릭 로그와 같은 implicit feedback을 인풋으로 사용할 수도 있겠지만 유저의 선호도/비선호도를 직접적으로 나타내지 않기 때문에 차선책일 뿐이라고 한다.
또한 확장성(Scalability)면에서도 한계가 있는데 유저들의 데이터가 쌓일수록 추천의 정확도는 더 높아지겠지만 그만큼 계산비용이 많이 든다는 딜레마가 있다. 예를 들어 아마존과 넷플릭스 같은 기업은 수백만명의 유저를 보유하고 있는데, 한 명의 타겟 유저에게 추천하기 위해 수백 번의 상관계수를 연산하는 것은 굉장히 비효율적일 것이다.
마지막으로 앞서 언급했던 콜드 스타트(Cold Start) 문제가 있다. 만약 신규 가입자가 생겼다면 이 유저는 이제 막 가입했기 때문에 이 유저에 대해서는 아직 아무런 평점 또는 구매 데이터가 쌓여있지 않다. 결과적으로 이 유저를 n차원의 벡터로 표현할 수 없고 비슷한 유저도 찾을 수 없다. 새로운 아이템의 경우에도 마찬가지이다. 아이템에 대한 유저들의 평가가 있어야 유사도를 계산할 수 있는데 아직 아무런 데이터가 없기 때문에 해당 아이템은 추천 결과에 포함될 수가 없다. 여기서 신규 아이템이 고객에게 노출되지 않는 문제가 생기는 것이다.
2. Item-based Collaborative Filtering (아이템 기반의 근접 이웃 방법)
앞서 User-based CF에는 확장성(scalability)이 부족하다는 단점이 있다고 언급했는데, 거대 기업들에게는 수백만 유저 간의 유사도를 계산하는 것이 다소 비효율적일 수 있다. 그래서 아마존은 이 한계를 극복하고자 Item-based Collaborative Filtering을 개발했다.
Item-based CF는 타겟 유저가 이미 평점을 주었거나 상호작용한 아이템과 비슷한 아이템을 찾는 방법이다. 즉 User-based CF에서는 유저간 유사도를 구했다면 Item-based CF에서는 아이템 간 유사도를 구한다.
예를 들어 아이템 A와 비슷한 아이템을 찾는다고 해보자. 여기서 아이템 간 유사도는 아이템 자체의 특성(features)들을 기준으로 측정하는 것이 아니라 (아이템 자체의 특성들을 사용하는 것은 contents-based CF) A 아이템을 구입한 다른 유저들이 대다수의 경우 B 아이템 또한 구입한, 또는 선호한 경우 두 아이템이 유사도가 높다고 보는 식이다. 따라서 유저-아이템 매트릭스에서 유저들이 준 평가를 기준으로 "아이템 간 유사도"를 구해야 한다.
※ item-based CF와 contents-based CF의 차이 (더보기 클릭)
In simple terms Item Based collaboration deals with the other user actions on the item you are looking at or buying. This type of filtering happens generally simultaneously and the attributes of the product doesn't have the importance in recommending . For ex- I am buying a ceiling Fan and then the system starts recommending me to buy a light (this is because many people who buy ceiling fans are also buying lights and not because light and ceiling fan are related , this information is generally extracted from the transcript of users )
Whereas when we talk about content based filtering , generally the pre-defined attributes of the products are matched and similar products will be recommended . For Ex- When a user buys a Cannon D450 Camera the system starts recommending lenses, other similar model camera (These recommendations are based on the fact that only those products related to the main item in some attributes like model or compatible lens etc . , and also these details about the product are taken from the stored data)
In item-to-item collaborative filtering you compare items based on users reviews. If your utility matrix has n users by m items you compare column vectors from this matrix.
In content based recommendation you compare items based on their features for movies things like title,genre,release date,director,producers,studio,etc.
Item-based CF
• 아이템 자체의 특성 간 유사도를 측정하는 것이 아니라 다른 유저의 행동이 반영된 유사도를 측정하는 것
• 다른 유저들의 리뷰, 평점을 기반으로 아이템 간 유사도 측정
• 예를 들어 ceiling fan을 사는데 lights를 추천받았다면, 이는 두 아이템의 특성이 비슷해서가 아니라 ceiling fan을 구매한 다른 유저들이 lights 또한 구매했거나 좋아했기 때문
• ex. 함께 클릭된 상품, 다른 유저가 함께 구매한 상품
Contents-based CF
• 아이템 자체의 특성이 비슷하면 추천 (ex. 영화 추천의 경우 장르, 개봉일, 감독 등)
• 아이템 자체의 특성들 간 유사도 측정
• ex. 비슷한 상품
이런 식으로 아이템 간 유사도를 측정하여 타겟 유저가 아직 접하지 않은 아이템(unobserved items)에 대한 타겟 유저의 평점을, 타겟 유저가 다른 유사한 아이템들에 준 평점을 기반으로 예측한 다음, 평점 예측값이 지정한 임계값을 넘으면 추천해주거나 예측한 평점이 높은 상위 n개의 아이템을 추천한다.

Ex.
Bob = {Matrix: 4, Kill Bill: 3, Terminator: 4}
items Bob not rated= {Robocop, Alien}
Bob이 Robocop과 Alien에 줄 평점을 Bob이 해당 작품들과 비슷한 아이템에 준 평점 정보를 기반으로 예측해야 함
이쯤에서 User-based CF와 Item-based CF의 차이를 한 번 짚고 넘어가자.
• User-based CF: "Users who are similar to you also liked ..."
• Item-base CF: "Users who liked this item also liked ..."
Collaborative filtering based systems use the actions of users to recommend other items. In general, they can either be user based or item based. User based collaborating filtering uses the patterns of users similar to me to recommend a product (users like me also looked at these other items). Item based collaborative filtering uses the patterns of users who browsed the same item as me to recommend me a product (users who looked at my item also looked at these other items). Item-based approach is usually prefered than user-based approach. User-based approach is often harder to scale because of the dynamic nature of users, whereas items usually don't change much, so item-based approach often can be computed offline.
Item-based CF의 step
1) 타겟 유저를 정한다.
2) 타겟 유저가 아직 평점을 주지 않은 아이템(unobserved item)과 유사한 이미 평점을 준 아이템들을 찾는다. (타 유저들의 아이템과의 상호작용(ex.평점)을 기반으로 아이템 간 유사도를 구함)
3) 유사 아이템들에 대한 타겟 유저의 평점을 기반으로 unobserved item에 대한 타겟 유저의 평점을 예측한다.
4) 예측한 평점이 임계값(threshold)보다 높다면 해당 unobserved items를 타겟 유저에게 추천한다. (또는 예측 평점이 높은 상위 n개의 아이템을 추천)
Item-based CF가 어떻게 이루어지는지 구체적으로 살펴보자.
STEP 1. 아이템 간 유사도 구하기
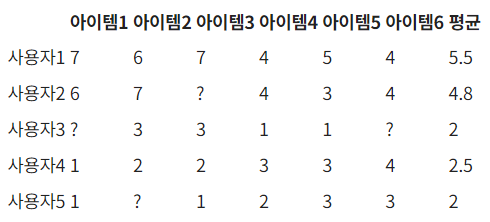
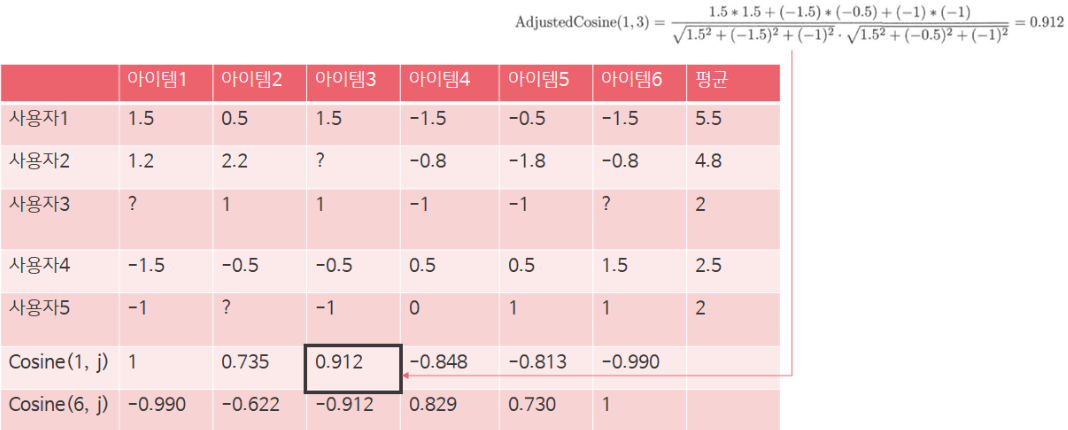
유사도를 구하는 방법은 User-based CF에서와 같고 이번에는 아이템 벡터 간 유사도를 구하면 된다. 유저-아이템 매트릭스에서 각 아이템 별 유저들의 평점이 아이템 벡터가 된다(아래 예시에서는 row 단위). 아래 예시에서는 피어슨 유사도를 사용했으며 분모에 유저들이 평점을 준 모든 아이템을 사용했다.

STEP 2. 타겟 유저의 평점 예측하기
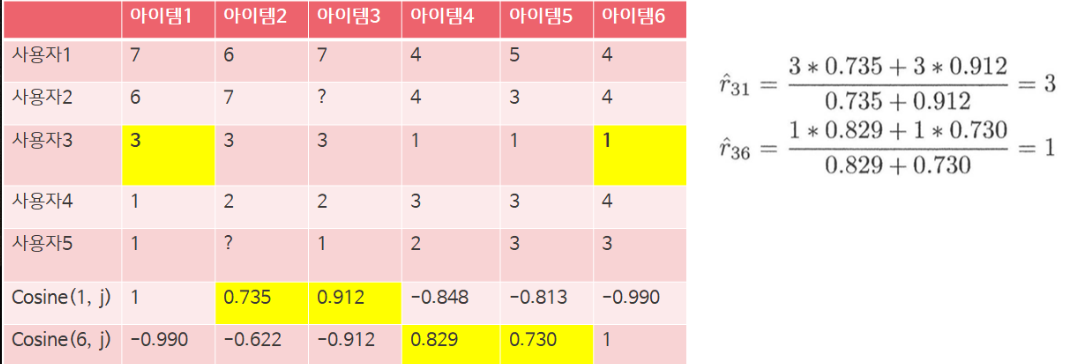
아이템 간 유사도를 구했다면 타겟 유저의 평점을 예측할 차례이다. 위 예시에서 |N|=2, 즉 2-Nearest Neighbors이므로 타겟 아이템과 가장 유사도가 높은 2개의 아이템을 사용하여 평점을 예측한다. 예측하려는 것은 타겟 유저 5의 아이템 1에 대한 평점이므로 타겟 유저가 이미 평점을 준 아이템들 중 아이템 1과 가장 유사도가 높은 2개의 아이템을 추출해야 한다. 계산한 유사도를 확인해보니 3, 4, 5, 6번 아이템들 중 3, 6번 아이템이 가장 유사하므로 타겟 유저가 이에 준 평점을 기반으로 아이템 1에 대한 평점을 예측한다.

아래 식을 보면 아이템 간 유사도를 가중치로 하여 가중 평균을 구한 것이 예측 평점이 된다.

또는


STEP 3. 타겟 유저에게 아이템 추천하기
이렇게 타겟 유저의 평점을 예측하여 유저-아이템 매트릭스의 빈칸을 모두 채웠다면 예측 평점이 높은 순으로 아이템을 내림차순 정렬하여 상위권에 랭크된 아이템들을 타겟 유저에게 추천해주거나, 예측 평점이 임계값(threshold)을 넘은 아이템들을 추천해 줄 수 있다.
[Item-based CF 예시] (더보기 클릭)
Item-based CF의 장점과 단점
아마존이나 넷플릭스 같은 거대 기업의 웹사이트에는 보통 가입 유저의 수가 아이템의 수보다 비교할 수 없을 정도로 많다. 유저가 늘어나는 속도 또한 신규 아이템이 생기는 속도보다 훨씬 더 빠르다. 이렇게 유저 pool은 크기도 크고 변화 속도도 빠른데에 비해 아이템 pool은 상대적으로 크기도 작고 변화 속도도 안정적인 편이다. 이러한 점에서 Item-based CF가 User-based CF에 비해 확장성과 효율적인 계산에 있어 유리해진다. User-based CF를 위한 유저간의 유사도 연산은 한번에 많이, 그리고 매번 수행해야 하지만 Item-based CF에서의 아이템 간 유사도 연산은 오프라인으로 미리 수행해두고 필요시에 결과값만 불러오는 방식으로 더 빠르게 처리할 수 있다고 한다.
(더보기 클릭)
Item based approach is usually preferred over user-based approach. User-based approach is often harder to scale because of the dynamic nature of users, whereas items usually don’t change much, and item based approach often can be computed offline and served without constantly re-training.
하지만 Item-based CF에도 콜드 스타트(Cold Start) 문제는 여전히 남아있다. 신규 아이템은 구매나 평점 데이터가 아직 없기 때문에 아이템 간 유사도 연산이 불가하고, 결국 추천 결과에도 포함되지 못한다. 신규 아이템 뿐만 아니라 구매/평점 데이터가 희소한(sparse) 아이템의 경우도 마찬가지다. 예를 들어, 두 아이템 간 유사도를 구하는데 두 아이템 모두를 구매/평가한 고객이 없는 경우 유사도 연산을 할 수 없고, 추천 결과에 포함될 가능성이 희박해진다.
User-based vs Item-based
user-based와 item-based 중 어떤 협업 필터링 방식이 나은지는 상황에 따라 다르지만, 유저 간 유사성보다 아이템 간 유사성이 더 신뢰할만하고 유의미하기 때문에 item-based 방식이 전반적으로 더 나은 결과를 보인다 (예를 들어, 위 예시에서 Alice가 선호도나 평점을 추후 바꾼다면 user-based method의 성능이 저하될 것). 즉, item-based methods는 유저보다는 변화가 적은 아이템에 의존하기 때문에 변화에 대해 더 안정적이다. 앞서 user-based CF와 item-based CF 각각의 장단점에 대해 설명하면서 언급한 확장성의 문제라고 할 수 있다. (유저 pool은 크기가 크고 변화가 빠른 반면, 아이템 pool은 그에 비해 크기가 작고 변화 속도가 안정적이다.)
Memory-based Collaborative Filtering의 장점과 단점
[장점]
- 학습과 최적화를 하지 않는 방식이기에 간단하고 접근 방식이 직관적이다. 따라서 구현 및 디버그가 쉽다.
- 특정 Item을 추천하는 이유를 정당화하기 쉽고, Item 기반 방법의 해석 가능성이 두드러진다.
- 설명하기도, 해석하기도 쉬운 만큼 적용하기도 쉬움
- 추천 리스트에 새로운 item과 user가 추가되어도 상대적으로 안정적
- 평점 데이터로 양의 선형 관계, 음의 선형 관계를 계산(유사도)하므로 평점 자체가 선호와 비선호를 나타내는 explicit dataset에 적합. 유저의 비선호도가 반영되지 않은 implicit dataset은 Latent Factor Model이 더 적합함
[단점]
- Cold Start (신규 유저, 아이템의 데이터 부재로 인한 문제)
- 계산 효율 저하
- ratings table의 사이즈가 커지면 유사도 함수(ex. 코사인, 피어슨)의 특성 때문에 unobserved areas의 ratings를 계산하는데에 걸리는 시간이 quadratic으로 증가한다.
- Long tail (인기 없는 아이템은 추천되지 않는 문제)
- ratings table의 Sparsity(희소성)에 영향을 많이 받음.
- sparse data인 경우 성능이 떨어지며, sparsity 때문에 실세계의 문제에 적용하는 데에 있어서 Scalability(확장성)가 떨어진다.
- Sparsity(희소성) 때문에 제한된 범위가 있음
- 타겟 유저의 Top-K 에만 관심이 있음
- 타겟 유저의 비슷한 이웃중에서 아무도 어떤 아이템을 평가하지 않았다면 타겟 유저의 해당 아이템에 대한 평점을 예측할 수 없음
- User-based CF의 경우 시간, 속도, 메모리가 많이 필요함 (Scalability(확장성)의 문제)

Recommender Systems
- Content-based Filtering
- Collaborative Filtering(CF)
• Memory-based CF (aka Neighborhood-based)
- User-based CF
- Item-based CF
• Model-based CF
References
1. Recommender Systems: Memory-based Collaborative Filtering Methods
2. Recommender Systems: What Long-Tail tells?
3. 집단지성에서 파생된 협업 필터링과 최신 추천 알고리즘 알아보기
4. 추천 알고리즘의 원리
6. Lecture 43 - Collaborative Filtering | Standford University (Youtube)⭐
7. 피어슨 상관 계수
8. 추천 시스템 04. User-based Collaborative Filtering 유저 기반 협업 필터링
10. 유사도의 종류와 파이썬 구현: 자카드 유사도, 피어슨 유사도, 코사인 유사도
11. [추천시스템] 유사도(Similarity) 구하는 방법
12. 03. 협업필터링 기반 추천시스템 - KNN ⭐
13. 갈아먹는 추천 알고리즘 [2] Collaborative Filtering
14. Various Implementations of Collaborative Filtering⭐
15. How Did We Build Book Recommender Systems in An Hour Part2 - k Nearest Neighbors and Matrix Factorization CF using K-Nearest Neighbors(KNN) ⭐
16. Prototyping a Recommender System Step by Step Part 1: KNN Item-Based Collaborative Filtering